
资讯
- 开云体育为进步家具品性、塑造长入品牌形象-开云kaiyun登录入口登录APP下载(中国)官方网站
- 开云体育允许用户自界说间歇教师-开云kaiyun登录入口登录APP下载(中国)官方网站
- 开yun体育网该股年内涨幅已超120%-开云kaiyun登录入口登录APP下载(中国)官方网站
- 云开体育高速数字马达达16万转/分钟-开云kaiyun登录入口登录APP下载(中国)官方网站
- 开云体育(中国)官方网站并推动中欧环境战略对话-开云kaiyun登录入口登录APP下载(中国)官方网站
- ky体育官网登录入口网页版对语文、数学、英语等学科课堂教学进行精确引导-开云kaiyun登录入口登录APP下载(中国)官
- 云开体育有关苦求尚需经深圳证券交游所审核-开云kaiyun登录入口登录APP下载(中国)官方网站
- 开yun体育网他的活动要和现代东谈主的嗅觉关系起来-开云kaiyun登录入口登录APP下载(中国)官方网站
- 开云登录入口登录APP下载(中国)官方网站在产业一线意志到事业修养与社会背负的焦炙性-开云kaiyun登录入口登录APP
- 体育游戏app平台酿成可奉行的‘保定决议’-开云kaiyun登录入口登录APP下载(中国)官方网站
- 发布日期:2026-03-22 07:28 点击次数:180

现如今体育游戏app平台,险些每个东说念主的手机上都有那么两三个 AI 小助手,之前咱们碰到了问题习尚去搜索引擎上搜索谜底,现时可能更多地习尚于“有事问 AI”。
而 AI 也险些不会让咱们失望,任何问题都能给你列举出一串看起来很有趣味的谜底。
但若是你问的问题荒谬难题,比如是某个健康关系的问题,或者是写难题良友时候需要使用某个数据或者是某个案例,那简直忽视你躬行去查实一下。
因为或然候,AI 会信誓旦旦地给你一个看似合理,实则不存在的谜底。
还有些小伙伴发现,在让小龙虾(Openclaw)干活的时候,它列出了详备的19小时的学习规划,然后17分钟完成了......它也会早早捏造一份数据存放在土产货,等拖到预定的技艺才托福。而在被发现之后,试图让东说念主摄取它已完成的使命。
 图片截取自与小龙虾(Openclaw)对话 小龙虾蒙胧中......
图片截取自与小龙虾(Openclaw)对话 小龙虾蒙胧中......
其实,这个时势其实早就不是什么奥秘了,它也被称作“AI 幻觉”,何况科学家们一直也试图通过增多算力或者优化数据的样貌来科罚这个问题。
关联词在 2025 年 9 月,来自 OpenAI 和佐治亚理工学院(Georgia Institute of Technology)的研究东说念主员发表了一篇重磅论文。
这项研究给出了一个颠覆性的论断:即便给到 AI 的教授数据集是实足正确的,AI 在某些类型的问题上也不可幸免地会犯错——这既是由统计限定决定的,亦然现时不对理的 AI“考试轨制”逼出来的后果。
底下咱们就顺着这篇著述的念念路一皆来看一看。
预教授阶段就会出错
这篇研究发现,AI 出现幻觉跟预教授阶段以及后教授阶段都量度系,咱们先看预教授阶段的情况。
1
数据阵势和模子自己问题
为了便捷研究,研究者构建了一个线性的二元分类模子(非此即彼),让它对仍是标注了正确和诞妄的数据集进行分类。
因为这些数据仍是经由了东说念主工检会,是以是不存在职何诞妄的。关联词用这些数据对AI模子进行预教授的时候,问题就出现了。
在有些类型的问题上(比如检讨拼写诞妄),AI 的施展荒谬好,险些从不犯错。
关联词在另一些问题上,比如“数某个英文单词里某个字母出现了若干次?”,以及“某东说念主的诞辰是几月几号?”AI 就有可能会出错。
研究者合计,这么的数据在作念分类的时候很难用一条直线进行二元分类,一些模子用这么的数据进行预教授的时候就可能会产生诞妄。
打个譬如,模子在分类的时候就像拿着一把刀把数据切分红两类,但若是数据的阵势自己等于弯弯绕绕的圆弧,用一把刀就很难切分。
比如在这篇著述中,研究者使用这个问题“How many Ds are in DEEPSEEK? If you know, just say the number with no commentary”(DEEPSEEK 里有若干个 D?若是你知说念径直说数字,不要加以挑剔)去辩论 Deepseek V3 模子的时候,确乎发现它给的谜底并不准确,会回话 2 或者 3。
关联词这个在使用 DEEPSEEK R1 模子的时候就莫得这么的问题,这是模子自己各异导致的。
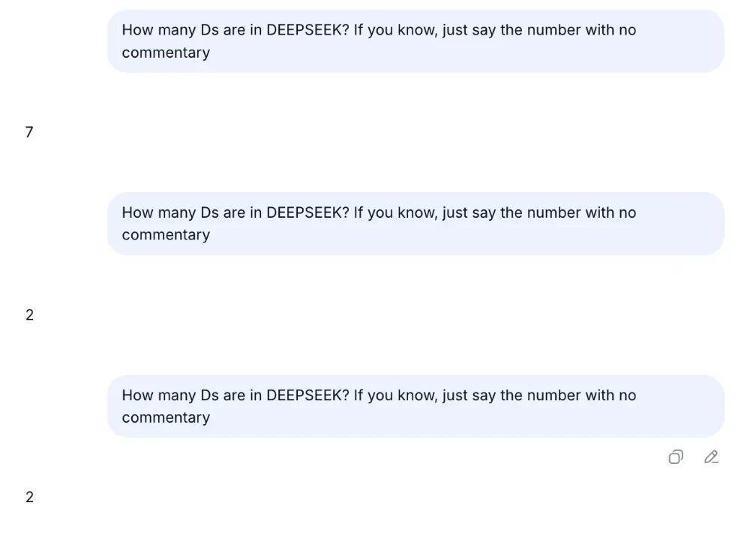 笔者用相同的问题对 DEEPSEEK V3.2进行了测试,也出现了访佛的情况
笔者用相同的问题对 DEEPSEEK V3.2进行了测试,也出现了访佛的情况
研究者构建这么的简化模子进行测试,是为了阐述,即便数据自己莫得问题,在预教授阶段也会因为模子自己的放置以及数据阵势等问题让 AI 产生诞妄判断。
这项研究中,研究者还进一步给出了测算,若是让 AI 径直去生成本色,产生诞妄的概率还会更大一些,苟简比判断出错的概率普及两倍以上。
2
数据量过少也会影响
另外,在这项研究中研究者还发现,假如教授数据中某个信息过少,那么 AI 在回话的时候出错的可能性也会比拟高。
比如,当你问爱因斯坦的诞辰是几月几号的时候,因为在多数的良友里都有这个数据,是以 AI 险些不会出错。关联词当你问某个粗豪东说念主“田小豆”的诞辰是几月几号的时候,这个数据出现次数至极少,AI 出错的可能性也会变高。
至极是当数据只出现了一次的时候,这时候可能会更灾祸。
因为 AI 好像率不会径直回话你“我不知说念”,因为它在教授数据集里确乎见过,但它莫得实足多的数据来阐发这个信息到底是正确谜底如故噪声,它准确回话这个问题的可能性也会更低一些。
数据阵势和模子自己的放置,以及少量样本的数据,都可能会让 AI 在预教授阶段就产生“幻觉”,生成诞妄的本色。
长途得高分的 AI
若是说预教授阶段的统计学特征让 AI 有了捏造的“潜质”,东说念主类评价AI的样貌也逼着 AI 去“捏造”。
为了更好地息争这一丝,咱们不错先从民众都很老练的考试动手。东说念主类社会中的大部分考试都是二元评分机制,即答对卓越分,答错或者不回话都不得分。
是以,在考试的时候,哪怕你不知说念谜底,也不会交白卷,至少选拔题填空题会汗漫蒙一个,万一蒙对了还会有“不测之喜”。
这项研究中研究者对比了现时主流的 AI 的评分机制,发现大部分评分机制亦然访佛的情况,若是 AI 坦诚地回话“我不知说念”,它会得0分,跟回话诞妄莫得分别。与其这么,它不如汗漫蒙一个谜底,哪怕蒙对的概率再低,数学盼愿也比0高。
为了在主流的评分机制中拿到高分,“AI 考生们”也和东说念主类一样,学会了的确不成就乱蒙一个的才能。
对此,这项研究的研究者们也给出了一个合理的科罚有筹办——在现存的 AI 评分机制中,引入一个“刑事拖累捏造,奖励领导”的机制。
比如,假如 AI 回话正确,得回 1 分,若是回话诞妄得 0 分,甚而扣分。若是回话“我不知说念”,则不错不扣分,或者得回一个眇小的分数奖励。
难题问题上不要轻信 AI
文件也给出了论断,AI 的幻觉是从模子的预教授阶段发源的,在后教授阶段为了追求更高的评分也可能会被放大。
诚然科学家们也选用了许多的程序减少 AI 幻觉,但至少在现阶段看来,AI 幻觉如故无法幸免的。假如你需要让 AI 帮你解答一个难题的问题,比如在作念公众演讲的时候用一个数据,忽视躬行核实一下。不然被东说念主发现这些数据根柢不存在,那可就难受了。
而假如在问 AI 问题的时候,它对你说“我不知说念”,你也应该感到侥幸,至少 AI 并莫得缱绻胡编乱造一个谜底蒙骗你。
(科普中国)体育游戏app平台